
Изображение создано при помощи модели Шедеврум
В интернете можно найти практически все. Но вручную извлечь из океана данных нужную информацию, особенно если речь идет о больших объемах, зачастую сложно и долго. В такой ситуации может быть полезен веб-скрейпинг. Что это такое, в каких сферах используется, из каких частей состоит процесс создания несложного Python-скрипта для сбора информации с сайта и какие есть ограничения в его применении рассказал старший преподаватель Департамента больших данных и информационного поиска факультета компьютерных наук НИУ ВШЭ Максим Карпов.
Веб-скрейпинг — это автоматизированный метод извлечения полезных данных с веб-страниц. Можно извлекать практически любую информацию: тексты статей, прайс-листы магазинов, описания продуктов, статистику посещений, рейтинги и отзывы, контактные данные организаций и даже медиафайлы.
Технически веб-скрейпинг применяется для сайтов, которые не запрещают автоматизированный сбор данных и не требуют использования интерфейса API (Application Programming Interface, программный интерфейс, который позволяет различным программным приложениям взаимодействовать друг с другом, обмениваться данными и использовать функциональность друг друга — Ред.) При этом на некоторых сайтах API может быть платным. Крайне важно всегда проверять правила сайта и использовать API, только если он доступен.
Максим Карпов обращает внимание, что существуют удобные инструменты для быстрой сборки данных без глубокого знания программирования: ParseHub, Octoparse, Google Sheets (IMPORTHTML). Они позволяют визуально выделять нужные блоки данных и автоматически сохранять их в файлы. Однако для более сложных задач и высокой точности всё же рекомендуется владение языками программирования и специализированными библиотеками.
Процесс веб-скрейпинга состоит из нескольких этапов:
1. Получение страницы: cначала запрашиваем нужную страницу сайта.
Специальная программа отправляет запрос к веб-странице, аналогично тому, как это делает браузер. В результате программа получает HTML-код страницы — её структурированное содержимое без графических элементов. Для этого этапа используется библиотека requests, которая упрощает работу с интернет-запросами.

2. Парсинг содержимого: извлекаем полезные данные из полученного HTML-документа с помощью библиотеки Beautiful Soup.
Этот инструмент анализирует структуру документа и помогает находить конкретные элементы: заголовки, абзацы текста, ссылки или таблицы. Например, можно извлечь все основные заголовки страницы.

3. Обработка и сохранение данных: преобразуем извлеченные данные в нужный формат (например, CSV).
Извлеченная информация приводится к структурированному виду при помощи библиотеки pandas. Данные организуются в табличном формате и сохраняются в CSV-файл, который можно открыть в электронных таблицах или специализированных программах для анализа.
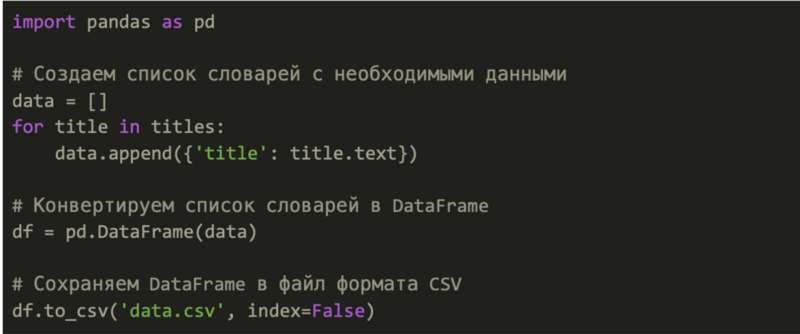
Теперь данные будут сохранены в формате .csv, удобном для дальнейшей обработки и анализа средствами pandas.
Python — язык программирования, который широко используется для анализа данных. Благодаря понятному синтаксису и богатым библиотекам он отлично подходит для новичков и профессионалов.
Beautiful Soup — библиотека Python для анализа HTML и XML документов, которая быстро разбирает структуру веб-страницы и помогает извлечь нужные данные: текст, ссылки, заголовки и т. д.
Selenium — инструмент, который используется для автоматизации действий браузера (позволяет открывать браузер, кликать по кнопкам, заполнять формы и даже ждать загрузки страницы). Может быть полезен для динамических сайтов с JavaScript.
Современные технологии позволяют автоматизировать процесс сбора и анализа данных с различных онлайн-источников, что находит применение во многих сферах деятельности, говорит Максим Карпов. В маркетинге и продажах это проявляется в автоматическом мониторинге ассортимента и цен конкурентов, отслеживании рыночных изменений для гибкого ценообразования, а также в анализе потребительских отзывов о продуктах и услугах. Финансовый сектор активно использует автоматизированный сбор котировок акций и валют с бирж и специализированных порталов, параллельно анализируя экономические новости для прогнозирования рыночной динамики.
В научной сфере и исследованиях автоматизация помогает изучать рынок труда, анализируя спрос на профессии и уровень зарплат в различных регионах, а также выявлять общественные настроения через мониторинг социальных сетей и медиа.
Сбор данных полезен также и на рынке недвижимости. Такие сервисы, как Циан, автоматически агрегируют объявления о продаже и аренде жилья, предоставляя аналитикам ценные данные о рыночных предложениях. Особое значение имеет работа с потребительскими отзывами: крупные торговые площадки, например, Яндекс.Маркет, систематизируют оценки и комментарии покупателей, что позволяет производителям и продавцам оперативно выявлять сильные и слабые стороны своих товаров, оперативно реагируя на обратную связь.
Также важно помнить, что при работе со сбором открытых данных есть определенные юридические ограничения, говорит эксперт. Нельзя нарушать правила пользования сайтом (например, если массовые запросы запрещены условиями сервиса), нельзя вторгаться в личную жизнь пользователей, обрабатывать персональные данные без согласия владельцев.
Необходимо соблюдать авторские права и законы о защите данных, в частности Федеральный закон «О персональных данных» №152-ФЗ от 27 июля 2006 года в России, GDPR (General Data Protection Regulation, общий регламент по защите данных — Ред.) в ЕС.
Перед началом веб-скрейпинга лучше ознакомиться с правилами сайта, а если планируется коммерческое использование собранных данных, то и проконсультироваться с юристом, подчеркивает Максим Карпов.
Авторы: Алла Мартыненко и Егор Поцелуйко, исследователи Проектно-учебной лаборатории экономической журналистики НИУ ВШЭ
В подписке — дайджест статей и видеолекций, анонсы мероприятий, данные исследований. Обещаем, что будем бережно относиться к вашему времени и присылать материалы раз в месяц.
Спасибо за подписку!
Что-то пошло не так!
{kind=link}